A picture says more than a thousand words, right? That’s why a web site needs images. In the old days before DD4T, the approach was very simple: out of the box, Tridion would publish your images to the file system, where the web server could pick them up and serve them out to the world.
But in the era of dynamic publishing, who wants to deploy to a file system anymore? One of the advantages of DD4T (or DXA, or any other dynamic framework) is that you publish everything to one central delivery store: the broker database. It makes sense to use this approach for images (and other binary file types) as well. But how?
Unfortunately, SDL does not offer an out of the box ‘serve binary files from the database’ feature. But (tadaaa!) DD4T does! It comes with a BinaryDistributionFilter (for .NET) and an AbstractBinaryController (for Java). Both make sure that the binary (when requested) is extracted from the database and served to the browser. Both also offer a resizing feature, so that you can have your images resized on the fly. A very useful feature, especially if you’re trying to create a responsive web site.
This approach has been tried and tested in many sites, and it works fine. But on a recent project of mine, we ended up choosing a completely different approach. The main reason for this, was the architecture that we chose: we put an Apache httpd server in front of our Tomcat application servers – a very common set up in the Java world! The idea – of course – being that you can let a fast web server like Apache serve the dumb content (javascript and CSS files, static images) and only channel requests to Tomcat if we need some ‘smartness’, like the ability to retrieve content from a CMS.
The diagram below shows how this worked out for us:
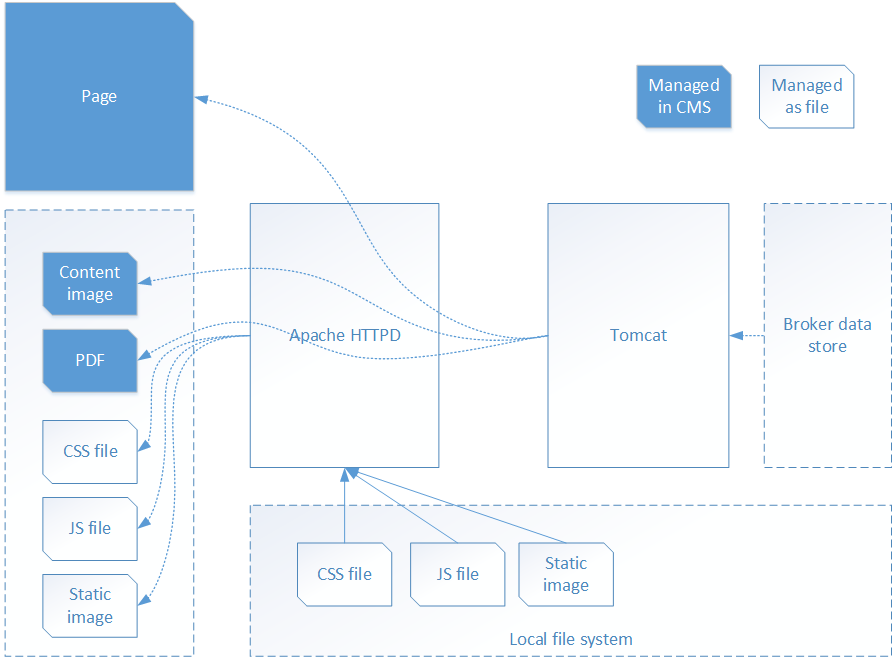
The downside of the standard DD4T approach becomes clear when you look at the diagram: although static files are served by HTTPD directly from the file system, that does not apply to files that are managed in Tridion (content images, PDFs, etc). Each request for such an item is handled by the application server. And of course, the web server is many times faster than the application server, and it can handle more concurrent requests.
An average web page (at least on our site) contains about 10 content images and other CMS-managed binaries. That means that our poor Tomcat appserver has to handle 11 requests for every single page we serve.
We started looking for a better approach, and we think we found one. The binary content managed in Tridion is rarely requested out of the blue. Almost always, the request is only made because the web page contains a reference to the file. For example: the HTML of the requested page may contain an img tag, which causes the browser to request the image in question. You could say that this allows us to predict which binary files will be requested a few milliseconds later. Why shouldn’t we extract the binary content from the broker data store when we extract the page, and store it as a file on the file system? Then, when the request for the binary content comes in, we can let Apache HTTPD handle it.
This is how it looks in a diagram:
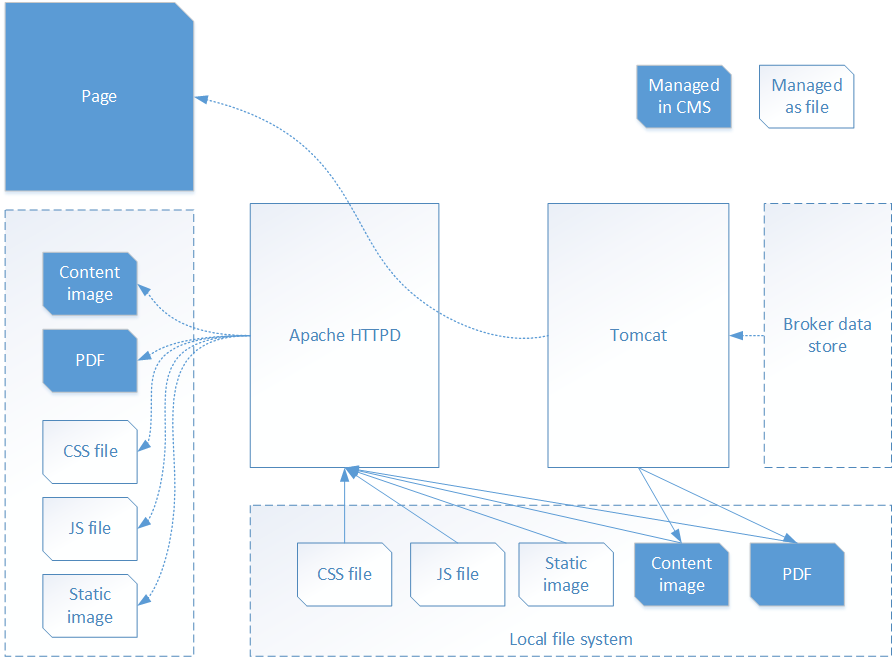
As you can see, less requests make it to the Tomcat application server. In our situation about 11 times less, in fact.
So how?
Neither DD4T nor DXA offer out-of-the-box solutions for the approach we wanted to take, so we had to roll our own. Since we are using Thymeleaf as a view language (see Using the Thymeleaf view language), we created a Thymeleaf dialect. A dialect is an extension to Thymeleaf. It allows you to add elements and/or attributes to the language. In our case, we added an attribute ‘cus:image’ which can be added to any element.
Our views contain code like this:
<th:block bin:binary="${article.image}" />
The expression ${article.image} refers to the multimedia link field ‘image’ in the schema ‘article’.
The code results in the following HTML:
<img src="/images/1/a/1a76e3bb8199dea87.png" width="640" height="480" />
And what’s more: a file called 1a76e3bb8199dea87.png is created on the local file system, in the folder /images/1/a. It contains the binary content of the multimedia component. The width and the height are calculated from the actual size of the image being requested.
If you want to show smaller versions of the images, just pass in a width and/or a height, like this:
<th:block bin:binary="${article.image}" width="320" />
In this case, just a width was specified, and the image is resized maintaining its original aspect ratio. As a result, the height becomes smaller as well:
<img src="/images/1/a/1a76e3bb8199dea87.png" width="320" height="240" />
One word about the image’s file name. It is a hash built up out of the original image’s file name and its last publication date. This means that each URL is always unique for one particular version of an image. The next time the page is requested, the dialect sees that the image is already there, and stops processing right away.
As soon as a new version is published, the hash will change and the image will receive a new URL. This means that browsers can never cache older versions of an image!
If you want, you can simply throw away all the image files from the local file system. They will be generated again when needed.
In case you’re wondering how Tomcat knows where to store the binary files: it is controlled through 2 system properties, which can be supplied in a standard java properties file. They are:
images.physicalpath: the physical location on the local file system where the images must be stored
images.url: the url where this folder can be reached through Apache.
Pros and cons
Is this the best solution in all cases? Probably not. Let’s look at the pros and cons. On the plus side, only one request to the application server is needed to serve an entire web page including all its content. On the other hand, that one request does take up more time. The benefit lies in the overhead of passing a request to Tomcat, and starting up an MVC context for each and every content image.
There is one significant downside: before you can request a binary file, the page which links to it must be requested first. I know there are some implementations where for example PDF documents are distributed directly. The URL of the PDF might be posted to Facebook directly, for example. In those cases, you are better off with the out-of-the-box DD4T or DXA approach, using a BinaryController.
Also, the approach has the most effect when you use Java. In the .NET world it is not customary to channel each request through a ‘plain web server’ before it hits the application server. In most cases IIS is used as a web and application server in one.
But if you are using Java, you definitely want to consider this approach!
Download
You can download the necessary source code here: BinaryDialect-src.
If you like it and think it should be part of DD4T permanently, just let me know. You can reach me through the regular Trivident contact page: http://www.trivident.com/contact/.