SDL Web 8 has been around for a little over a year now. Its successor (SDL Web 8.5) was recently introduced. You’d think that to an old Tridion hand like me, by now Web 8.x would be as familiar as any of the earlier (Tridion) versions. The sobering fact is that today I ran into an issue caused by a poor understanding on my side of SDL’s new microservices architecture. Fortunately it proved easy to fix.
Here is the situation. We have a web farm consisting of 2 servers. Both have an identical setup:
- An application server
- A discovery service
- A content service
In other words: we put all the services that are needed to serve a web page on a single box. By doing so we’re able to reduce network latency to a minimum.
In terms of configuration, it’s quite simple. The application server contains a file called cd_client_conf.xml, which contains the address of the discovery service (footnote: we’re doing Java here, on .NET you would put a key in the Web.config instead).
The discovery service contains a file called cd_storage_conf.xml, which (among other things) contains the address of the content service.
We made the decision to reference servers by their machine name, rather than ‘localhost’. So the application server on machine A was referencing the discovery service on machine A, which in turn was referencing the content service on machine A.
Makes sense, right?
Wrong! After a while we started noticing that the content service on server B was not receiving any traffic at all. Instead, the discovery service on server B appeared to point to the content service on server A.
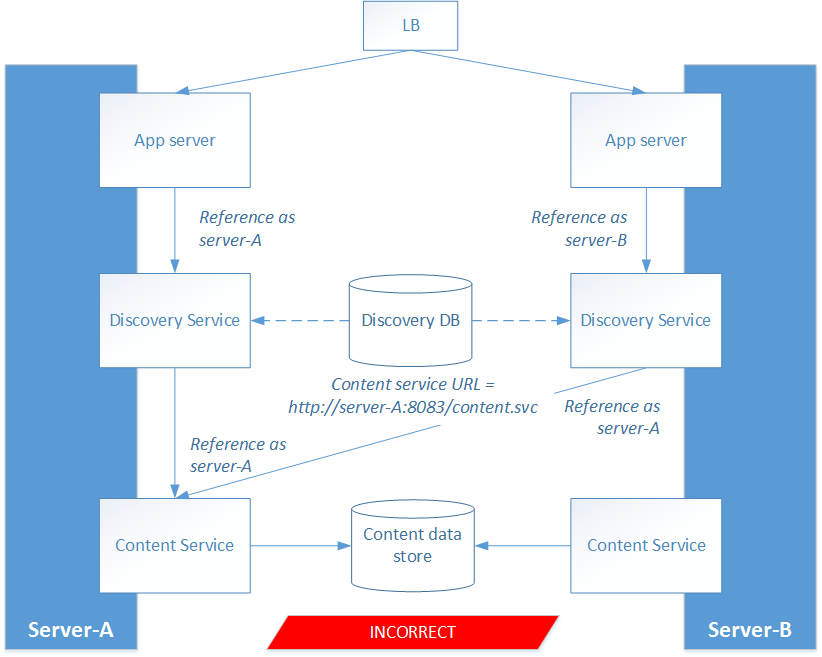
What was going on here? The problem was that even though the discovery service contains a config file which points to a content service, this config file is never used at runtime! Whenever you change this configuration, you need to run an update script which copies the information to a Discovery database (see http://docs.sdl.com/LiveContent/content/en-US/SDL%20Web-v1/GUID-521FDAD2-9188-4B1C-A44C-BBC51F44FE40). At runtime, the configuration is read from this database and NOT from the config file.
In our case, we used a single Discovery database for both servers. In hindsight it is clear what went wrong:
- We configured the URL of the content service on server B to be ‘http://server-B:8083/content.svc’
- We ran the update script on server B
- The Discovery DB now contained the address http://server-B:8083/content.svc
- We configured the URL of the content service on server A to be ‘http://server-A:8083/content.svc’
- We ran the update script on server A
- The Discovery DB now contained the address http://server-A:8083/content.svc
There are several ways to solve this issue. One option is to create separate Discovery databases for each server. However, that means more configuration to take care of, and more things to do if you ever want to add a third server to the web farm.
There are two alternative scenarios which are better. Both have pros and cons.
Scenario 1: reference the content service as ‘localhost’
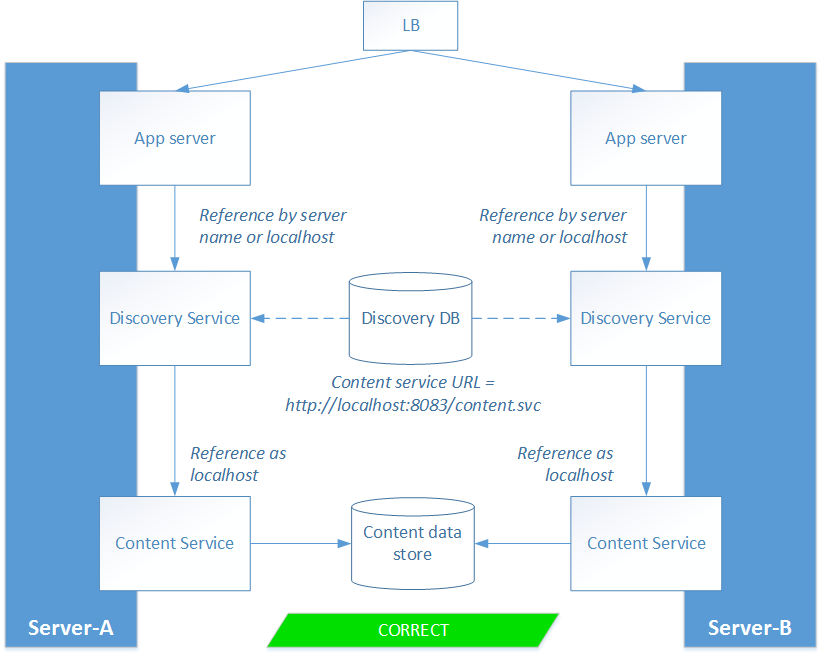
The trick here is that ‘localhost’ has a different meaning depending on who’s asking. If you call ‘localhost’ on server A, you mean server A, whereas if you call ‘localhost’ on server B, you mean server B.
Scenario 2: load balance the microservices
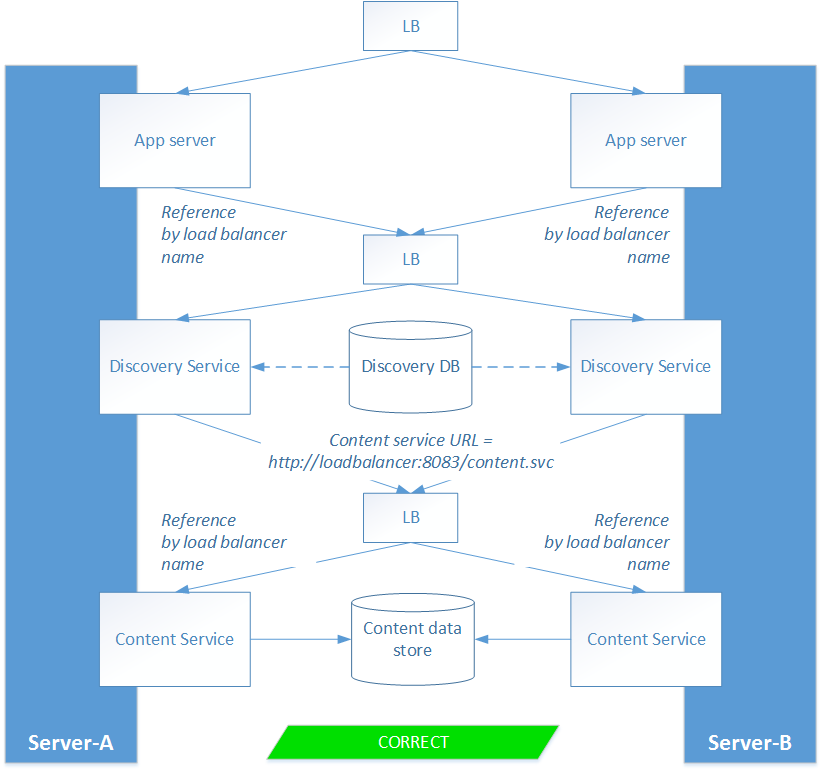
This works because both servers use the same load balancer address.
Both scenarios work fine. But which one is better? The answer – as so often – is: it depends on what you want.
Are you looking for maximum performance? Then go with scenario 1. All services are on one server, so there is no network latency.
Is it robustness that you’re after, then scenario 2 is a better option. You can shut down any of the micro services and the system will automatically fail over to the other node. However, your request may take a little longer to process, because it can be handled by services on different servers.
To be fair: fail-over could be achieved in scenario 1 as well, but it depends on the capabilities of your load balancer.
Hopefully, this bit of background info from a guy who’s made mistakes, will help you to avoid them yourself!